Mysql встроенные функции. Практика использования функции count MySQL
Внимание! Данная работа построена на основе перевода раздела «17.1. Stored Routines and the Grant Tables» описания ПО MySQL 5.0.19, «Reference Manual. It documents MySQL 5.0 through 5.0.19. Document generated on: 2006-01-23 (revision:995)»
``Сначала прочти все, а потом пробуй примеры"
Хранимые процедуры представляют собой набор команд SQL, которые могут компилироваться и храниться на сервере. Таким образом, вместо того, чтобы хранить часто используемый запрос, клиенты могут ссылаться на соответствующую хранимую процедуру. Это обеспечивает лучшую производительность, поскольку данный запрос должен анализироваться только однажды и уменьшается трафик между сервером и клиентом. Концептуальный уровень можно также повысить за счет создания на сервере библиотеки функций.
Триггер представляет собой хранимую процедуру, которая активизируется при наступлении определенного события. Например, можно задать хранимую процедуру, которая срабатывает каждый раз при удалении записи из транзакционной таблицы - таким образом, обеспечивается автоматическое удаление соответствующего заказчика из таблицы заказчиков, когда все его транзакции удаляются.
Хранимые программы (процедуры и функции) поддерживаются в MySQL 5.0. Хранимые процедуры - набор SQL -выражений, который может быть сохранен на сервере. Как только это сделано, клиенту уже не нужно повторно передавать запрос, а требуется просто вызвать хранимую программу.
Это может быть полезным тогда, когда:
- многочисленные приложения клиента написаны в разных языках или работают на других платформах, но нужно использовать ту же базу данных операций
- безопасность на 1 месте
Хранимые процедуры и функции (подпрограммы) могут обеспечить лучшую производительность потому, что меньше информации требуется для пересылки между клиентом и сервером. Выбор увеличивает нагрузку на сервер БД, но снижает затраты на стороне клиента. Используйте это, если много клиентских машин (таких как Веб-серверы) обслуживаются одной или несколькими БД.
Хранимые подпрограммы также позволяют вам использовать библиотеки функций, хранимые в БД сервера. Эта возможность представлена для многих современных языков программирования, которые позволяют вызывать их непосредственно (например, используя классы).
MySQL следует в синтаксисе за SQL:2003 для хранимых процедур, который уже используется в IBM"s DB2.
От слов к делу…
При создании, модификации, удалении хранимых подпрограмм сервер манипулирует с таблицей mysql.proc
Начиная с MySQL 5.0.3 требуются следующие привилегии:
CREATE ROUTINE для создания хранимых процедур
ALTER ROUTINE необходимы для изменения или удаления процедур. Эта привилегия автоматически назначается создателю процедуры (функции)
EXECUTE привилегия потребуется для выполнения подпрограммы. Тем не менее, автоматически назначается создателю процедуры (функции). Также, по умолчанию, SQL SECURITY параметр для подпрограммы DEFINER , который разрешает пользователям, имеющим доступ к БД вызывать подпрограммы, ассоциированные с этой БД.
Синтаксис хранимых процедур и функций
Хранимая подпрограмма представляет собой процедуру или функцию. Хранимые подпрограммы создаются с помощью выражений CREATE PROCEDURE или CREATE FUNCTION . Хранимая подпрограмма вызывается, используя выражение CALL , причем только возвращающие значение переменные используются в качестве выходных. Функция может быть вызвана подобно любой другой функции и может возвращать скалярную величину. Хранимые подпрограммы могут вызывать другие хранимые подпрограммы.
Начиная с MySQL 5.0.1, загруженная процедура или функция связана с конкретной базой данных. Это имеет несколько смыслов:
- Когда подпрограмма вызывается, то подразумевается, что надо произвести вызов USE db_name (и отменить использование базы, когда подпрограмма завершилась, и база больше не потребуется)
- Вы можете квалифицировать обычные имена с именем базы данных. Это может быть использовано, чтобы ссылаться на подпрограмму, которая - не в текущей базе данных. Например, для выполнения хранимой процедуры p или функции f которые связаны с БД test , вы можете сказать интерпретатору команд так: CALL test.p() или test.f() .
- Когда база данных удалена, все загруженные подпрограммы связанные с ней тоже удаляются. В MySQL 5.0.0, загруженные подпрограммы - глобальные и не связанны с базой данных. Они наследуют по умолчанию базу данных из вызывающего оператора. Если USE db_name выполнено в пределах подпрограммы, оригинальная текущая БД будет восстановлена после выхода из подпрограммы (Например текущая БД db_11 , делаем вызов подпрограммы, использующей db_22 , после выхода из подпрограммы остается текущей db_11)
MySQL поддерживает полностью расширения, которые разрешают юзать обычные SELECT выражения (без использования курсоров или локальных переменных) внутри хранимых процедур. Результирующий набор, возвращенный от запроса, а просто отправляется напрямую клиенту. Множественный SELECT запрос генерирует множество результирующих наборов, поэтому клиент должен использовать библиотеку, поддерживающую множественные результирующие наборы.
CREATE PROCEDURE - создать хранимую процедуру.
CREATE FUNCTION - создать хранимую функцию.
Синтаксис:
CREATE PROCEDURE имя_процедуры ([параметр_процедуры[,...]])[характеристёика...] тело_подпрограммы
CREATE FUNCTION
имя_функции ([параметр_функции[,...]])
RETURNS
тип
[характеристика...] тело_подпрограммы
параметр_процедуры:
[ IN
| OUT
| INOUT
] имя_параметра тип
параметр_функции:
имя_параметра тип
тип:
Любой тип данных MySQL
характеристика:
LANGUAGE SQL
| DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT "string"
тело_подпрограммы:
Правильное SQL выражение.
Рассмотрим все на практике.
Сначала создадим хранимую процедуру следующим запросом:
CREATE PROCEDURE `my_proc`(OUT t INTEGER(11))
NOT DETERMINISTIC
SQL SECURITY INVOKER
COMMENT ""
BEGIN
select val1+val2 into "t" from `my` LIMIT 0,1;
END;
Применение выражения LIMIT в этом запросе сделано из соображений того, что не любой клиент способен принять многострочный результирующий набор.
После этого вызовем ее:
CALL my_proc(@a);
SELECT @a;
Для отделения внутреннего запроса от внешнего всегда используют разделитель отличный от обычно (для задания используют команду DELIMITER <строка/символ>)
Вот еще один пример с учетом всех требований.
Mysql> delimiter //
mysql> CREATE PROCEDURE simpleproc (OUT param1 INT)
-> BEGIN
-> SELECT COUNT(*) INTO param1 FROM t;
-> END;
-> //
mysql> delimiter ;
mysql> CALL simpleproc(@a);
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @a;
+------+
| @a |
+------+
| 3 |
+------+
1 row in set (0.00 sec)
Весь процесс можно пронаблюдать на рисунке ниже:
Триггеры
Поддержка триггеров появилась в MySQL начиная с версии 5.0.2.
Триггер - поименованный объект БД, который ассоциирован с таблицей и активируемый при наступлении определенного события, события связанного с этой таблицей.
Например, нижеприведенный код создает таблицу и INSERT триггер. Триггер суммирует значения, вставляемые в один из столбцов таблицы.
Mysql> CREATE TABLE account (acct_num INT, amount DECIMAL(10,2));
Query OK, 0 rows affected (0.03 sec)
mysql> CREATE TRIGGER ins_sum BEFORE INSERT ON account
-> FOR EACH ROW SET @sum = @sum + NEW.amount;
Query OK, 0 rows affected (0.06 sec)

Объявим переменную sum и присвоим ей значение 1. После этого при каждой вставке в таблицу account значение этой переменной будет увеличивать согласно вставляемой части.
Замечание . Если значение переменной не инициализировано, то триггер работать не будет!

Синтаксис создания триггера
CREATETRIGGER имя_триггера время_триггера событие_срабатывания_триггера
ON имя_таблицы FOR EACH ROW выражение_выполняемое_при_срабатывании_триггера
Если с именем триггера и именем пользователя все понятно сразу, то о «времени триггера» и «событии» поговорим отдельно.
время_триггера
Определяет время свершения действия триггера. BEFORE означает, что триггер выполнится до завершения события срабатывания триггера, а AFTER означает, что после. Например, при вставке записей (см. пример выше) наш триггер срабатывал до фактической вставки записи и вычислял сумму. Такой вариант уместен при предварительном вычислении каких-то дополнительных полей в таблице или параллельной вставке в другую таблицу.
событие_срабатывания_триггера
Здесь все проще. Тут четко обозначается, при каком событии выполняется триггер.
- INSERT: т.е. при операциях вставки или аналогичных ей выражениях (INSERT, LOAD DATA, и REPLACE)
- UPDATE: когда сущность (строка) модифицирована
- DELETE: когда запись удаляется (запросы, содержащие выражения DELETE и/или REPLACE)
■ В MySQL предлагает широкий выбор встроенных операторов и функций, которые могут оказаться полезными при создании запросов. Большинство этих функций предназначено для использования в выражениях SELECT и WHERE. Существуют также некоторые специальные функции группировки для использования в выражении GROUP BY. Число доступных для использования функций очень велико, поэтому мы рассмотрим только наиболее полезные из них.
Здесь следует сделать одно важное замечание . В MySQL любое выражение, содержащее NULL, оценивается как NULL.
Операторы
В MySQL используются три главных типа операторов: знаки арифметических операций, операторы сравнения и логические операторы . Арифметические операции
В MySQL используются обычные арифметические операции: сложение (+), вычитание (-), умножение (*) и деление (/). Деление на нулевое значение дает безопасный результат NULL.
Операторы сравнения
При работе с операторами сравнения необходимо помнить о том, что, за исключением нескольких особо оговариваемых случаев, сравнение чего-либо со значением NULL дает в результате NULL.
Рассмотрим операторы сравнения. Наиболее часто используемые из них приведены в таблице
 |

Типы таблиц MySQL
Проектирование системы управления базой данных, подобно многим другим задачам проектирования, подразумевает множество компромиссных решений. Например, многие задачи базы данных должны обеспечиваться решениями, предполагающими безопасность транзакций, но такие решения требуют больше времени для их выполнения, больше дискового пространства и памяти. Создатели MySQL делегировали выбор некоторых из компромиссных решений вам, разработчику базы данных, предложив на выбор несколько типов таблиц. В зависимости от приложения вы можете выбрать один из типов таблиц, обеспечивающих безопасность транзакций, или же с помощью другого типа обеспечить более высокую производительность, не гарантируя безопасность транзакций. Так или иначе, необходимо знать, какие компромиссы вы при этом допускаете.
Вы уже могли обратить внимание, что типы таблиц мы называли механизмами хранения. Это отражает тот факт, что некоторые из типов таблиц используют большие самостоятельные фрагменты программного кода со своими системами кэширования, индексации, блокировки и доступа к диску. Это отражает также суть назначения базы данных: хранение информации.
Представьте на минуту, что вы имеете дело с базой данных, содержащей информацию о банковских счетах. Если необходимо перевести 1000 долларов с одного счета на другой, вам потребуется как минимум два запроса SQL: один, чтобы снять 1000 долларов с одного счета, и еще один, чтобы добавить 1000 долларов ко второму счету. Существует опасность (например, в случае отключения электропитания), что один запрос завершит свою работу, а второй - нет. Было бы очень желательно, чтобы в подобных случаях завершиться успешно могли либо оба из пары запросов, либо ни один из них, чтобы данные в базе данных остались согласованными.
Чтобы обеспечить безопасность транзакций, таблицы должны предусматривать возможность указания того, что некоторый набор запросов должен трактоваться как одна неделимая единица - транзакция . Транзакция должна либо завершиться полностью, либо база данных должна выполнить откат, т.е. возвратиться к тому же состоянию, которое имело место до начала выполнения транзакции.
К типам таблиц, доступных в MySQL, относятся следующие:
■ BerkeleyDB (BDB)
Безопасность транзакций обеспечивают таблицы InnoDB и BerkeleyDB. Остальные (ISAM, MylSAM, MERGE и HEAP) безопасность транзакций не обеспечивают.
Таблицы ISAM
Таблицы ISAM включены в MySQL исключительно для поддержки совместимости. Их функциональные возможности полностью поддерживаются таблицами MyISAM.
Таблицы ISAM предлагают быстрый, но не защищенный с точки зрения транзакций, механизм хранения данных. Практически все, что можно сказать о таблицах ISAM, будет верно и для таблиц MyISAM, но относящиеся к более старому стандарту таблицы ISAM имеют ряд ограничений.
Улучшения, предложенные в таблицах MyISAM, включают следующее.
■ Мобильность таблиц. Таблицы, сохраненные на диске или другом носителе, можно загрузить в другую систему, поддерживающую MySQL, независимо от платформы. Для таблиц ISAM это не так.
■ Поддержка очень больших таблиц. Размеры таблицы ISAM имеют жесткое ограничение - 4 Гбайт. MyISAM позволяет создавать таблицы настолько большие, насколько большими им позволяет быть операционная система, в которой выполняется MySQL. Это может оказаться важным небольшому числу пользователей, но это означает, что к выбору операционной (и файловой) системы следует отнестись весьма внимательно. Многие файловые системы имеют ограничение 2 Гбайт для размера файла. (Обратите внимание на то, что это ограничение можно на самом деле обойти, используя таблицы MERGE.)
■ Более эффективное использование дискового пространства. Сокращен объем пустого пространства и уменьшена фрагментация.
■ Меньшие ограничения на ключи. Таблицы ISAM допускают использование 16 ключей на таблицу и максимальную длину ключа по умолчанию 256 байт. Таблицы MyISAM допускают 64 ключа на таблицу и максимальную длину ключа по умолчанию 1024 байт.
Таблицы ISAM должны восприниматься как нежелательные.
Таблицы MyISAM
Таблицы MyISAM обеспечивают очень быстрый, но не защищенный с точки зрения транзакций, механизм хранения данных. Они обеспечивают высокую производительность в большинстве ситуаций даже при наличии ошибок в структуре базы данных
Таблицы MyISAM могут быть одного из трех типов: динамические, статические или сжатые . Таблица автоматически становится динамической или статической в зависимости от определения ее столбцов. Сжатые таблицы должны создаваться специально с помощью средства myisampack.
Таблицы со строками фиксированной длины будут статическими, а таблицы со строками переменной длины - динамическими.
Статическая таблица имеет целый ряд преимуществ. Она обеспечивает более быстрый поиск по сравнению с динамической или сжатой таблицей. Для базы данных очень легко извлечь конкретную запись на основе индекса, когда каждая запись находится на определенном расстоянии от начала файла. Данные проще кэшировать. Менее вероятно возникновение серьезных повреждений в случае отказа системы - возможности восстановления данных, как правило, легко обеспечивают восстановление всех строк, кроме одной поврежденной.
Недостатком статических таблиц является то, что размещение реальных данных в столбцах фиксированного размера, очевидно, не способствует экономии дискового пространства. Это может быть не слишком большой ценой для данных варьирующих в небольших пределах (например, для имен пользователей), но может оказаться неприемлемым для данных, которые сильно варьируют в размерах.
Динамические таблицы в рамках MySQL требуют более сложных методов управления. В этом случае и кэширование, и поиск, и восстановление записей для механизма хранения оказываются не такими простыми задачами. Причиной отчасти является то, что данные варьируют в размерах, но также и то, что они могут оказаться фрагментированными. Если строка изменяется и становится больше, часть данных останется на исходном месте, а часть может сохраниться в виде нового фрагмента где-нибудь в другом месте файла. Это значит, что сегмент файла, помещенный в кэш операционной системой, не обязательно будет содержать все части соответствующей строки. Могут возникнуть трудности и при восстановлении повреждений, поскольку в случае потери фрагментов или ссылок будет совсем не очевидно, каким строкам должны принадлежать распознанные части данных.
Таблицы InnoDB
Следующим типом таблиц, который мы будем обсуждать, является тип InnoDB. Данный тип представляет собой механизм хранения, обеспечивающий быструю работу и безопасность транзакций. Таблицы InnoDB предлагают следующие возможности.
■Транзакции.
■Блокировка на уровне строк. Это означает, что при выполнении запроса недоступной для других пользователей будет только строка, используемая в данном запросе. Большинство других механизмов хранения (за исключением BDB) предлагает блокировку на уровне таблиц - пока один процесс обновляет таблицу, таблица не доступна другим процессам.
■Поддержка внешних ключей. Примеры из предыдущих глав, в которых используются внешние ключи, не будут работать с другими типами таблиц.
■Согласованное неблокирующее чтение в операторах SELECT. (Эта идея позаимствована из Oracle.)
Механизм InnoDB имеет свои собственные опции настройки, отдельный каталог и свои особенности хранения данных. В то время как механизм MyISAM для хранения каждой таблицы использует отдельный файл, механизм InnoDB хранит все таблицы и индексы в специальном пространстве таблиц, и это означает, что содержимое одной таблицы может размещаться в нескольких файлах. Это дает возможность механизму InnoDB создавать очень большие таблицы, которые не обязаны подчиняться каким-либо ограничениям на размеры файлов, налагаемым операционной системой. Однако, следует учитывать то, что для хранения одного и того же объема полезной информации таблицы InnoDB используют значительно больше дискового пространства, чем таблицы MylSAM.
InnoDB является одной из самых быстрых систем, обеспечивающих безопасность транзакций, но обеспечение этой безопасности требует жертв. Для большинства реальных сценариев таблицы MyISAM будут быстрее, но разница, в общем, не будет слишком впечатляющей.
Тема 5. Язык HTML как средство внешнего представления данных .
Несмотря на то, что в настоящее время существует огромное количество программных продуктов, которые позволяют создавать сайты в режиме "What you see and what you get" (Что видите, то и получаете), после сохранения документа в качестве web-страницы получается html файл. HTML файл - это обычный текстовый документ, который может быть написан в любом текстовом редакторе (например, блокнот) и сохранён с расширением *.htm или *.html. Многие программы, которые позволяют создавать сайты по готовым шаблонам, имеют встроенный html редактор. Знание html необходимо для более полного контроля всех элементов, которые располагаются на вашей странице (текст, рисунки, таблицы, flash эффекты, java аплеты…), а также для внесения каких-либо исправлений в ходе обслуживания сайта.
HTML (HyperText Markup Language)- язык гипертекстовой разметки. Он позволяет:-публиковать электронные документы с заголовками, текстом, таблицами, списками, фотографиями и т.д. в сети интернет;
Загружать электронную информацию с помощью щелчка мыши на гипертекстовой ссылке;
Разрабатывать формы для выполнения операций с удаленными службами, для использования в поиске информации, резервировании, заказе продуктов и т.д;
Включать электронные таблицы, видеоклипы, звуковые фрагменты и другие приложения непосредственно в документы
В этой части статьи допишем начатую в предыдущей статье хранимую процедуру и научимся создавать хранимые mysql функции .
И так нам осталось указать значение для последней переменной PostID. В качестве значения ей будет присвоен результат, который вернёт функция GetPostID, которую сейчас и создадим.
Создание функции
Для начала закрываем текущую форму создания процедуры, нажав на кнопку c надписью Go. Затем в этом же окне снова нажимаем на надпись Add routine, появится знакомая форма, заполним её.
Имя - GetPostID Тип - функция Parameters - ComID BIGINT(20) UNSIGNED Return type (возвращаемый тип) - BIGINT Return length/values - 20 Return options - UNSIGNED Definition: BEGIN RETURN (SELECT comment_post_ID FROM wp_comments WHERE comment_ID = ComID); END;
Так же можно указать дополнительные параметры:
Is deterministic — детерминированная функция всегда возвращает один и тот же результат при одинаковых входных параметрах иначе она является не детерминированной. В нашем случае ставим галочку.
Definer и Security type параметры безопасности, в данном примере оставим их без изменений.
SQL data access имеет несколько значений:
NO SQL - не содержит sql.
Contains SQL - содержит встроенные sql функции или операторы, которые не читают, не пишут и не изменяют данные в базе данных. Например, установка значения переменной: SET name = значение;
READS SQL DATA - только чтение данных, без любой модификации данных, указывается для запроса SELECT.
MODIFIES SQL DATA - изменение или внесение данных, в базу данных, указывается для запросов: INSERT, UPDATE, но при этом не должен присутствовать запрос SELECT.
В нашей функции используется запрос SELECT, укажем READS SQL DATA.
Comment комментарий.
После того как все поля заполнены, нажимаем на кнопку с надписью Go.
Возвращаемся на вкладку Routines и отредактируем нашу процедуру, нажав на кнопку edit.

Присвоим переменой PostID в качестве значения результат, который вернёт функция GetPostID.
SET postID = GetPostID(ComID);
В результате окончательное тело процедуры будет таким
BEGIN DECLARE Author tinytext DEFAULT "admin"; DECLARE UserID bigint(20) DEFAULT 1; DECLARE Email varchar(100); DECLARE Date DATETIME DEFAULT NOW(); DECLARE ParentCom varchar(20); DECLARE Approved varchar(20); DECLARE PostID BIGINT(20); IF Author = "admin" THEN SET Approved = 1; ELSE SET Approved = 0; END IF; SET ParentCom = ComID ; SET Email = "[email protected]"; SET PostID = GetPostID(ComID); INSERT INTO wp_comments (comment_author, comment_author_email, comment_content, comment_date, comment_date_gmt, comment_post_id, comment_parent, comment_approved, user_id) VALUES (Author, Email, Content, Date, Date, PostID, ParentCom, Approved, UserID); END;
Остальные поля формы оставим без изменений, нажимаем на кнопку Go. Процедура создана.
Так же можно установить значения для одной или нескольких переменных в результате выполнения запроса. Например, поля: Автор, почта и id пользователя хранятся в таблице wp_users.
Зная это можно установить значения для этих переменных следующим образом:
BEGIN -- Объявляем переменные DECLARE Author tinytext DEFAULT "admin"; DECLARE UserID bigint(20) DEFAULT 1; DECLARE Email varchar(100); -- выполнение запроса и установка значений для переменных SELECT user_login, user_email, ID INTO Author, Email, UserID FROM wp_users WHERE user_login LIKE "adm%"; END;
Вызов хранимой процедуры
Осталось протестировать созданную процедуру. Для начала добавим комментарий к любой статье, одобрим его и проверим, чтобы он отображался на странице.

Затем узнаем id добавленного комментария

Возвращаемся на вкладку Routines и нажимаем на надпись Execute
Появится форма
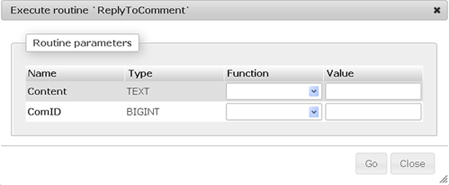
Указываем значения передаваемых параметров: текст ответа и id комментария, после чего нажимаем на кнопку с надписью Go.

Современная база данных MySQL не критична к количеству записей. В контроле выхода за допустимые границы количества строк редко возникает необходимость.
Между тем, существует множество задач, когда структура базы данных сама по себе является существенным данным и использование таблиц должно контролироваться в количестве записей вообще и конкретном содержании в частности.
Синтаксис функции и пример использования
Функция count MySQL используется непосредственно в запросе к базе данных. У функции есть всего две основных формы применения: все записи или только конкретные. Есть только один существенный фактор - выбираемая строка по полю, которое входит в выражение count(), не должна иметь значение NULL.

В приведённом примере функция count MySQL используется без условий. Следует обратить внимание, что использование count (*) - это обращение ко всем записям таблицы и совершенно не имеет значения, что в некоторых записях может быть значение NULL. Запрос, содержащий count(*) выдаст всегда всё количество записей, которое содержится в таблице.
Разработчик может предусмотреть смысл выражения:
- count(...) as result.
Но оно будет иметь больше наглядное значение, нежели практическое.
Безопасность PHP & MySQL: count() - на практике
Вопросам безопасности посвящено множество усилий самой квалифицированной когорты разработчиков. Но по сей день находятся бреши, происходят атаки, теряется или крадётся ценная информация.

Есть только два самых надёжных и безопасных барьера на пути любого злоумышленника:
- незнание;
- отклонение.
Первый барьер - самый железобетонный. Можно строить догадки о чём угодно, но, если не знаешь куда, зачем и каким образом, - эффекта не будет никогда. Всегда нужна дверь, которую следует открыть, ключ к ней и уважительная причина, чтобы заниматься этим.
В контексте второго решения функции count(*) и count (...) MySQL - примеры идеальной защиты. Самое главное - эти функции безусловны и примитивны . Они будут исполнены при любом положений вещей, главное, чтобы сама база данных работала и было установлено с ней соединение.
Простроив таблицу безопасности таким образом, чтобы каждый вход/выход сотрудника компании отмечался состоянием NULL или не NULL, можно контролировать все отклонения, которые происходят в течение рабочего времени дня. Естественно выходные, праздничные и нерабочее время рабочего дня должны сбрасывать все записи таблицы безопасности в значение NULL.
Даже при такой примитивной логике можно заметить и предотвратить любое непредвиденное вторжение самым простым способом, без особых затрат. Чем проще и незаметнее защита, тем сложнее построить вторжение.
Условия и особые случаи
В приведённом ниже примере используется условие, согласно которому в операции count MySQL участвуют не все записи таблицы.

Результат исполнения всех запросов соответствует условию. При этом использование запроса:
- select param1 + param2 + param3 from `ex_count` where count(*)
эквивалентно запросу
- select count(*) from `ex_count` where (param1 + param2 + param3) > 0.
Функция count MySQL допускает различные варианты применения, в том числе во вложенных запросах. Однако всегда следует принимать во внимание: простота - залог успеха. Функция подсчета количества записей по тем или иным условиям слишком проста, но не следует её применение делать слишком сложным.

На самую крепкую защиту есть верный ключик - «случай» - что в транслитерации на простой язык означает «закономерность». Так и на сложное применение простых операций вроде count MySQL иной пытливый ум разработчика может повесить такой функционал, который в непредвиденной ситуации сработает вовсе не так, как было задумано.
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Практическая работа
Функции в MySQL
Задание 1. Встроенные функции
математический функция программирование
Функции - это операции, позволяющие манипулировать данными. В MySQL можно выделить несколько групп встроенных функций:
Строковые функции . Используются для управления текстовыми строками, например, для обрезания или заполнения значений.
Числовые функции . Используются для выполнения математических операций над числовыми данными. К числовым функциям относятся функции возвращающие абсолютные значения, синусы и косинусы углов, квадратный корень числа и т.д. Используются они только для алгебраических, тригонометрических и геометрических вычислений. В общем, используются редко, поэтому рассматривать их мы не будем. Но вы должны знать, что они существуют, и в случае необходимости обратиться к документации MySQL.
Итоговые функции . Используются для получения итоговых данных по таблицам, например, когда надо просуммировать какие-либо данные без их выборки.
Функции даты и времени . Используются для управления значениями даты и времени, например, для возвращения разницы между датами.
Системные функции . Возвращают служебную информацию СУБД.
Для того, чтобы рассмотреть основные встроенные функции нам понадобится создать новую базу данных, чтобы в ней были числовые значения и значения даты.
Давайте в качестве примера рассмотрим интернет-магазин.
Концептуальная модель:
Реляционная модель:
Итак, смотрим на последнюю схему и создаем БД - shop.
create database shop;
Выбираем ее для работы:
И создаем в ней 8 таблиц, как в схеме: Покупатели (customers), Поставщики (vendors), Покупки (sale), Поставки (incoming), Журнал покупок (magazine_sales), Журнал поставок (magazine_incoming), Товары (products), Цены (prices). Один нюанс, наш магазин будет торговать книгами, поэтому в таблицу Товары мы добавим еще один столбец - Автор (author), в принципе это необязательно, но так как-то привычнее.
Обратите внимание, что в таблицах Журнал покупок, Журнал поставок и Цены первичные ключи - составные, т.е. их уникальные значения состоят из пар значений (в таблице не может быть двух строк с одинаковыми парами значений). Названия столбцов этих пар значений и указываются через запятую после ключевого слова PRIMARY KEY.
В настоящем интернет-магазине данные в эти таблицы будут заноситься посредством сценариев на каком-либо языке (типа php), нам же пока придется внести их вручную. Можете внести любые данные, только помните, что значения в одноименных столбцах связанных таблиц должны совпадать. Либо скопируйте нижеприведенные данные:
Итак, в нашем магазине 24 наименования товара, привезенные в трех поставках от трех поставщиков, и совершенно три продажи. Все готово, можем приступать к изучению встроенных функций MySQL.
Задание 2 . Итоговые функции, вычисляемые столбцы и представления
Итоговые функции еще называют статистическими, агрегатными или суммирующими. Эти функции обрабатывают набор строк для подсчета и возвращения одного значения. Таких функций всего пять:
AVG() Функция возвращает среднее значение столбца.
COUNT() Функция возвращает число строк в столбце.
MAX() Функция возвращает самое большое значение в столбце.
MIN() Функция возвращает самое маленькое значение в столбце.
SUM() Функция возвращает сумму значений столбца.
С одной из них - COUNT() - мы уже познакомилисьhttp://www.site-do.ru/db/sql8.php. Сейчас познакомимся с остальными. Предположим, мы захотели узнать минимальную, максимальную и среднюю цену на книги в нашем магазине. Тогда из таблицы Цены (prices) надо взять минимальное, максимальное и среднее значения по столбцу price. Запрос простой:
SELECT MIN(price), MAX(price), AVG(price) FROM prices;
Теперь, мы хотим узнать, на какую сумму нам привез товар поставщик "Дом печати" (id=2). Составить такой запрос не так просто. Давайте поразмышляем, как его составить:
Сначала надо из таблицы Поставки (incoming) выбрать идентификаторы (id_incoming) тех поставок, которые осуществлялись поставщиком "Дом печати" (id=2):
Теперь из таблицы Журнал поставок (magazine_incoming) надо выбрать товары (id_product) и их количества (quantity), которые осуществлялись в найденных в пункте 1 поставках. То есть запрос из пункта 1 становится вложенным:
Теперь нам надо добавить в результирующую таблицу цены на найденные товары, которые хранятся в таблице Цены (prices). То есть нам понадобится объединение таблиц Журнал поставок (magazine_incoming) и Цены (prices) по столбцу id_product:
В получившейся таблице явно не хватает столбца Сумма, то есть вычисляемого столбца. Возможность создания таких столбцов предусмотрена в MySQL. Для этого надо лишь указать в запросе имя вычисляемого столбца и что он должен вычислять. В нашем примере такой столбец будет называться summa, а вычислять он будет произведение столбцов quantity и price. Название нового столбца отделяется словом AS:
Отлично, нам осталось лишь просуммировать столбец summa и наконец-то узнаем, на какую сумму нам привез товар поставщик "Дом печати". Синтаксис для использования функции SUM() следущий:
SELECT SUM(имя_столбца) FROM имя_таблицы;
Имя столбца нам известно - summa, а вот имени таблицы у нас нет, так как она является результатом запроса. Что же делать? Для таких случаев в MySQL существуют Представления. Представление - это запрос на выборку, которому присваивается уникальное имя и который можно сохранять в базе данных, для последующего использования.
Синтаксис создания представления следующий:
CREATE VIEW имя_представления AS запрос;
Давайте сохраним наш запрос, как представление с именем report_vendor:
CREATE VIEW report_vendor AS
SELECT magazine_incoming.id_product, magazine_incoming.quantity, prices.price,
magazine_incoming.quantity*prices.price AS summa
FROM magazine_incoming, prices
WHERE magazine_incoming.id_product= prices.id_product AND id_incoming=
Вот теперь можно использовать итоговую функцию SUM():
Вот мы и достигли результата, правда для этого нам пришлось использовать вложенные запросы, объединения, вычисляемые столбцы и представления. Да, иногда для получения результата приходится подумать, без этого никуда. Зато мы коснулись двух очень важных тем - вычисляемые столбцы и представления. Давайте поговорим о них поподробнее.
Вычисляемые поля (столбцы)
На примере мы рассмотрели математическое вычисляемое поле. Здесь хотелось бы добавить, что использовать можно не только операцию умножения (*), но и вычитание (-), и сложение (+), и деление (/). Синтаксис следующий:
SELECT имя_столбца_1, имя_столбца_2, имя_столбца_1*имя_столбца_2 AS имя_вычисляемого_столбца
FROM имя_таблицы;
Второй нюанс - ключевое слово AS, мы его использовали для задания имени вычисляемого столбца. На самом деле с помощью этого ключевого слова задаются псевдонимы для любых столбцов. Зачем это нужно? Для сокращения и читаемости кода. Например, наше представление могло бы выглядеть так:
CREATE VIEW report_vendor AS
SELECT A.id_product, A.quantity, B.price, A.quantity*B.price AS summa
FROM magazine_incoming AS A, prices AS B
WHERE A.id_product= B.id_product AND id_incoming=
(SELECT id_incoming FROM incoming WHERE id_vendor=2);
Согласитесь, что так гораздо короче и понятнее.
Представления
Синтаксис создания представлений мы уже рассматривали. После создания представлений, их можно использовать так же, как таблицы. То есть выполнять запросы к ним, фильтровать и сортировать данные, объединять одни представления с другими. С одной стороны это очень удобный способ хранения частоприменяемых сложных запросов (как в нашем примере).
Но следует помнить, что представления - это не таблицы, то есть они не хранят данные, а лишь извлекают их из других таблиц. Отсюда, во-первых, при изменении данных в таблицах, результаты представления так же будут меняться. А во-вторых, при запросе к представлению происходит поиск необходимых данных, то есть производительность СУБД снижается. Поэтому злоупотреблять ими не стоит.
Строковые функции Sql
Эта группа функций позволяет манипулировать текстом. Строковых функций много, мы рассмотрим наиболее употребительные.
CONCAT(str1,str2...)
Возвращает строку, созданную путем объединения аргументов (аргументы указываются в скобках - str1,str2...). Например, в нашей таблице Поставщики (vendors) есть столбец Город (city) и столбец Адрес (address). Предположим, мы хотим, чтобы в результирующей таблице Адрес и Город указывались в одном столбце, т.е. мы хотим объединить данные из двух столбцов в один. Для этого мы будем использовать строковую функцию CONCAT(), а в качестве аргументов укажем названия объединяемых столбцов - city и address:
Обратите внимание, объединение произошло без разделения, что не очень читабельно. Давайте подправим наш запрос, чтобы между объединяемыми столбцами был пробел:
Как видите, пробел считается тоже аргументом и указывается через запятую. Если объединяемых столбцов было бы больше, то указывать каждый раз пробелы было бы нерационально. В этом случае можно было бы использовать строковую функцию CONCAT_WS(разделитель, str1,str2...), которая помещает разделитель между объединяемыми строками (разделитель указывается, как первый аргумент). Наш запрос тогда будет выглядеть так:
SELECT CONCAT_WS(" ", city, address) FROM vendors;
Результат внешне не изменился, но если бы мы объединяли 3 или 4 столбца, то код значительно бы сократился.
INSERT(str, pos, len, new_str)
Возвращает строку str, в которой подстрока, начинающаяся с позиции pos и имеющая длину len символов, заменена подстрокой new_str. Предположим, мы решили в столбце Адрес (address) не отображать первые 3 символа (сокращения ул., пр., и т.д.), тогда мы заменим их на пробелы:
То есть три символа, начиная с первого, заменены тремя пробелами.
LPAD(str, len, dop_str) Возвращает строку str, дополненную слева строкой dop_str до длины len. Предположим, мы хотим, чтобы при выводе городов поставщиков они располагались бы справа, а пустое пространство заполнялось бы точками:
RPAD(str, len, dop_str)
Возвращает строку str, дополненную справа строкой dop_str до длины len. Предположим, мы хотим, чтобы при выводе городов поставщиков они располагались бы слева, а пустое пространство заполнялось бы точками:
Обратите внимание, значение len ограничивает количество выводимых символов, т.е. если название города будет длиннее 15 символов, то оно будет обрезано.
Возвращает строку str, в которой удалены все начальные пробелы. Эта строковая функция удобна для корректного отображения информации в случаях, когда при вводе данных допускаются случайные пробелы:
SELECT LTRIM(city) FROM vendors;
Возвращает строку str, в которой удалены все конечные пробелы:
SELECT RTRIM(city) FROM vendors;
В нашем случае лишних пробелов не было, поэтому и результат внешне мы не увидим.
Возвращает строку str, в которой удалены все начальные и конечные пробелы:
SELECT TRIM(city) FROM vendors;
Возвращает строку str, в которой все символы переведены в нижний регистр. С русскими буквами работает некорректно, поэтому лучше не применять. Например, давайте применим эту функцию к столбцу city:
Видите, какая абракадабра получилась. А вот с латиницей все в порядке:
Возвращает строку str, в которой все символы переведены в верхний регистр. С русскими буквами так же лучше не применять. А вот с латиницей все в порядке:
Возвращает длину строки str. Например, давайте узнаем сколько символов в наших адресах поставщиков:
Возвращает len левых символов строки str. Например, пусть в городах поставщиков выводится только первые три символа:
Возвращает len правых символов строки str. Например, пусть в городах поставщиков выводится только последние три символа:
Возвращает строку str n-количество раз. Например:
REPLACE(str, pod_str1, pod_str2)
Возвращает строку str, в которой все подстроки pod_str1 заменены подстроками pod_str2. Например, пусть мы хотим, чтобы в городах поставщиков вместо длинного "Санкт-Петербург" выводилось короткое "СПб":
Возвращает строку str, записанную в обратном порядке:
LOAD_FILE(file_name)
Эта функция читает файл file_name и возвращает его содержимое в виде строки. Например, создайте файл proverka.txt, напишите в нем какой-нибудь текст (лучше латиницей, чтобы не было проблем с кодировками), сохраните его на диске С и сделайте следующий запрос:
Обратите внимание, необходимо указывать абсолютный путь к файлу.
Как уже упоминалось строковых функций гораздо больше, но даже некоторые рассмотренные здесь применяются крайне редко. Поэтому на этом закончим их рассмотрение и перейдем к более используемым функциям даты и времени.
Задание 3 . Функции даты и времени
Эти функции предназначены для работы с календарными типами данных. Рассмотрим наиболее применимые.
CURDATE(), CURTIME() и NOW()
Первая функция возвращает текущую дату, вторая - текущее время, а третья - текущую дату и время. Сравните:
Функции CURDATE() и NOW() удобно использовать для добавления в базу данных записей, использующих текущее время. В нашем магазине все поставки и продажи используют текущее время. Поэтому для добавления записей о поставах, и продажах удобно использовать функцию CURDATE(). Например, пусть в наш магазин пришел товар, давайте добавим информацию об этом в таблицу Поставка (incoming):
Если бы мы хранили дату поставки с типом datatime, то нам больше подошла бы функция NOW().
ADDDATE(date, INTERVAL value) Функция возвращает дату date, к которой прибавлено значение value. Значение value может быть отрицательным, тогда итоговая дата уменьшится. Давайте посмотрим, когда наши поставщики делали поставки товара:
Предположим, мы ошиблись при вводе даты для первого поставщика, давайте уменьшим его дату на одни сутки:
В качестве значения value могут выступать не только дни, но и недели (WEEK), месяцы (MONTH), кварталы (QUARTER) и годы (YEAR). Давайте для пример уменьшим дату поставки для второго поставщика на 1 неделю:
В нашей таблице Поставки (incoming) мы использовали для столбца Дата поставки (date_incoming) тип date. Этот тип данных предназначен для хранения только даты. А вот если бы мы использовали тип datatime, то у нас отображалась бы не только дата, но и время. Тогда мы могли бы использовать функцию ADDDATE и для времени. В качестве значения value в этом случае могут выступать секунды (SECOND), минуты (MINUTE), часы (HOUR) и их комбинации:
минуты и секунды (MINUTE_SECOND),
часы, минуты и секунды (HOUR_SECOND),
часы и минуты (HOUR_MINUTE),
дни, часы, минуты и секунды (DAY_SECOND),
дни, часы и минуты (DAY_MINUTE),
дни и часы (DAY_HOUR),
года и месяцы (YEAR_MONTH).
SUBDATE(date, INTERVAL value)
функция идентична предыдущей, но производит операцию вычитания, а не сложения.
PERIOD_ADD(period, n)
функция добавляет n месяцев к значению даты period. Нюанс: значение даты должно быть представлено в формате YYYYMM. Давайте к февралю 2011 (201102) прибавим 2 месяца:
TIMESTAMPADD(interval, n, date)
функция добавляет к дате date временной интервал n, значения которого задаются параметром interval. Возможные значения параметра interval:
FRAC_SECOND - микросекунды
SECOND - секунды
MINUTE - минуты
WEEK - недели
MONTH - месяцы
QUARTER - кварталы
TIMEDIFF(date1, date2)
вычисляет разницу в часах, минутах и секундах между двумя датами.
DATEDIFF(date1, date2)
вычисляет разницу в днях между двумя датами. Например, мы хотим узнать, как давно поставщик "Вильямс" (id=1) поставлял нам товар:
PERIOD_DIFF(period1, period2)
функция вычисляет разницу в месяцах между двумя датами, представленными в формате YYYYMM. Давайте узнаем разницу между январем 2010 и августом 2011:
TIMESTAMPDIFF(interval, date1, date2)
функция вычисляет разницу между датами date2 и date1 в единицах, указанных в параметре interval. Возможные значения параметра interval:
FRAC_SECOND - микросекунды
SECOND - секунды
MINUTE - минуты
WEEK - недели
MONTH - месяцы
QUARTER - кварталы
SUBTIME(date, time)
функция вычитает из времени date время time:
возвращает дату, отсекая время. Например:
возвращает время, отсекая дату. Например:
функция принимает дату date и возвращает полный вариант со временем. Например:
DAY(date) и DAYOFMONTH(date)
функции-синонимы, возвращают из даты порядковый номер дня месяца:
DAYNAME(date), DAYOFWEEK(date) и WEEKDAY(date)
функции возвращают день недели, первая - его название, вторая - номер дня недели (отсчет от 1 - воскресенье до 7 - суббота), третья - номер дня недели (отсчет от 0 - понедельник, до 6 - воскресенье:
WEEK(date), WEEKOFYEAR(datetime)
обе функции возвращают номер недели в году, первая для типа date, а вторая - для типа datetime, у первой неделя начинается с воскресенья, у второй - с понедельника:
MONTH(date) и MONTHNAME(date)
обе функции возвращают значения месяца. Первая - его числовое значение (от 1 до 12), вторая - название месяца:
функция возвращает значение квартала года (от 1 до 4):
YEAR(date) функция возвращает значение года (от 1000 до 9999):
возвращает порядковый номер дня в году (от 1 до 366):
возвращает значение часа для времени (от 0 до 23):
MINUTE(datetime)
возвращает значение минут для времени (от 0 до 59):
SECOND(datetime)
возвращает значение секунд для времени (от 0 до 59):
EXTRACT(type FROM date)
возвращает часть date определяемую параметром type:
TO_DAYS(date) и FROM_DAYS(n)
взаимообратные функции. Первая преобразует дату в количество дней, прошедших с нулевого года. Вторая, наоборот, принимает число дней, прошедших с нулевого года и преобразует их в дату:
UNIX_TIMESTAMP(date) и FROM_UNIXTIME(n)
взаимообратные функции. Первая преобразует дату в количество секунд, прошедших с 1 января 1970 года. Вторая, наоборот, принимает число секунд, с 1 января 1970 года и преобразует их в дату:
TIME_TO_SEC(time) и SEC_TO_TIME(n)
взаимообратные функции. Первая преобразует время в количество секунд, прошедших от начала суток. Вторая, наоборот, принимает число секунд с начала суток и преобразует их во время:
MAKEDATE(year, n)
функция принимает год и номер дня в году и преобразует их в дату:
Задание 4. Ф ункции форматирования даты и времени
Эти функции также предназначены для работы с календарными типами данных. Рассмотрим их подробнее.
DATE_FORMAT(date, format)
форматирует дату date в соответствии с выбранным форматом formate. Эта функция очень часто используется. Например, в MySQL дата имеет формат представления YYYY-MM-DD (год-месяц-число), а нам привычнее формат DD-MM-YYYY (число-месяц-год). Поэтому для привычного нам отображения даты ее необходимо переформатировать. Давайте сначала приведем запрос, а затем разберемся, как задавать формат:
Теперь дата выглядит для нас привычно. Для задания формата даты используются специальные определители. Для удобства перечислим их в таблице.
|
Описание |
||
|
Сокращенное наименование дня недели (Mon - понедельник, Tue - вторник, Wed - среда, Thu - четверг, Fri - пятница, Sat - суббота, Sun - воскресенье). |
||
|
Сокращенное наименование месяцев (Jan - январь, Feb - февраль, Mar - март, Apr - апрель, May - май, Jun - июнь, Jul - июль, Aug - август, Sep - сентябрь, Oct - октябрь, Nov - ноябрь, Dec - декабрь). |
||
|
Месяц в числовой форме (1 - 12). |
||
|
День месяца в числовой форме с нулем (01 - 31). |
||
|
День месяца в английском варианте (1st, 2nd...). |
||
|
День месяца в числовой форме без нуля (1 - 31). |
||
|
Часы с ведущим нулем от 00 до 23. |
||
|
Часы с ведущим нулем от 00 до 12. |
||
|
Минуты от 00 до 59. |
||
|
День года от 001 до 366. |
||
|
Часы c ведущим нулем от 0 до 23. |
||
|
Часы без ведущим нуля от 1 до 12. |
||
|
Название месяца без сокращения. |
||
|
Месяц в числовой форме с ведущим нулем (01 - 12). |
||
|
АМ или РМ для 12-часового формата. |
||
|
Время в 12-часовом формате. |
||
|
Секунды от 00 до 59. |
||
|
Время в 24-часовом формате. |
||
|
Неделя (00 - 52), где первым днем недели считается понедельник. |
||
|
Неделя (00 - 52), где первым днем недели считается воскресенье. |
||
|
Название дня недели без сокращения. |
||
|
Номер дня недели (0 - воскресенье, 6 - суббота). |
||
|
Год, 4 разряда. |
||
|
Год, 2 разряда. |
STR_TO_DATE(date, format)
функция обратная предыдущей, она принимает дату date в формате format, а возвращает дату в формате MySQL.
.
TIME_FORMAT(time, format)
функция аналогична функции DATE_FORMAT(), но используется только для времени:
GET_FORMAT(date, format)
функция возвращает строку форматирования, соответствующую одному из пяти форматов времени:
EUR - европейский стандарт
USA - американский стандарт
JIS - японский индустриальный стандарт
ISO - стандарт ISO (международная организация стандартов)
INTERNAL - интернациональный стандарт
Эту функцию хорошо использовать совместно с предыдущей -
Посмотрим на примере:
Как видите, сама функция GET_FORMAT() возвращает формат представления, а вместе с функцией DATE_FORMAT() выдает дату в нужном формате. Сделайте сами запросы со всеми пятью стандартами и посмотрите на разницу .
Ну вот, теперь вы знаете о работе с датами и временем в MySQL практически все. Это вам очень пригодится при разработке различных web-приложений. Например, если пользователь в форму на сайте вводит дату в привычном ему формате, вам не составит труда применить нужную функцию, чтобы в БД дата попала в нужном формате.
Задание 5. Хранимые процедуры
Как правило, мы в работе с БД используем одни и те же запросы, либо набор последовательных запросов. Хранимые процедуры позволяют объединить последовательность запросов и сохранить их на сервере. Это очень удобный инструмент, и сейчас вы в этом убедитесь. Начнем с синтаксиса:
CREATE PROCEDURE
имя_процедуры (параметры)
операторы
Параметры это те данные, которые мы будем передавать процедуре при ее вызове, а операторы - это собственно запросы. Давайте напишем свою первую процедуру и убедимся в ее удобстве. Когда мы добавляли новые записи в БД shop, мы использовали стандартный запрос на добавление вида:
INSERT INTO customers (name, email) VALUE ("Иванов Сергей", "[email protected]");
Т.к. подобный запрос мы будем использовать каждый раз, когда нам необходимо будет добавить нового покупателя, то вполне уместно оформить его в виде процедуры:
CREATE PROCEDURE ins_cust(n CHAR(50), e CHAR(50))
insert into customers (name, email) value (n, e);
Обратите внимание, как задаются параметры: необходимо дать имя параметру и указать его тип, а в теле процедуры мы уже используем имена параметров. Один нюанс. Как вы помните, точка с запятой означает конец запроса и отправляет его на выполнение, что в данном случае неприемлемо. Поэтому, прежде, чем написать процедуру необходимо переопределить разделитель с; на "//", чтобы запрос не отправлялся раньше времени. Делается это с помощью оператора DELIMITER //:
Таким образом, мы указали СУБД, что выполнять команды теперь следует после //. Следует помнить, что переопределение разделителя осуществляется только на один сеанс работы, т.е. при следующем сеансе работы с MySql разделитель снова станет точкой с запятой и при необходимости его придется снова переопределять. Теперь можно разместить процедуру:
Итак, процедура создана. Теперь, когда нам понадобится ввести нового покупателя нам достаточно ее вызвать, указав необходимые параметры. Для вызова хранимой процедуры используется оператор CALL, после которого указывается имя процедуры и ее параметры. Давайте добавим нового покупателя в нашу таблицу Покупатели (customers):
Согласитесь, что так гораздо проще, чем писать каждый раз полный запрос. Проверим, работает ли процедура, посмотрев, появился ли новый покупатель в таблице Покупатели (customers):
Появился, процедура работает, и будет работать всегда, пока мы ее не удалим с помощью оператора DROP PROCEDURE название_процедуры.
Как было сказано в начале задания, процедуры позволяют объединить последовательность запросов. Давайте посмотрим, как это делается. Попробуем узнать, на какую сумму нам привез товар поставщик "Дом печати"? Раньше для этого нам пришлось бы использовать вложенные запросы, объединения, вычисляемые столбцы и представления. А если мы захотим узнать, на какую сумму нам привез товар другой поставщик? Придется составлять новые запросы, объединения и т.д. Проще один раз написать хранимую процедуру для этого действия.
Казалось бы, проще всего взять уже написанные представление и запрос к нему, объединить в хранимую процедуру и сделать идентификатор поставщика (id_vendor) входным параметром, вот так:
Но так процедура работать не будет. Все дело в том, что в представлениях не могут использоваться параметры. Поэтому нам придется несколько изменить последовательность запросов. Сначала мы создадим представление, которое будет выводить идентификатор поставщика (id_vendor), идентификатор продукта (id_product), количество (quantity), цену (price) и сумму (summa) из трех таблиц Поставки (incoming), Журнал поставок (magazine_incoming), Цены (prices):
А потом создадим запрос, который просуммирует суммы поставок интересующего нас поставщика, например, с id_vendor=2:
SELECT SUM(summa) FROM report_vendor WHERE id_vendor=2;
Вот теперь мы можем объединить два этих запроса в хранимую процедуру, где входным параметром будет идентификатор поставщика (id_vendor), который будет подставляться во второй запрос, но не в представление:
Проверим работу процедуры, с разными входными параметрами:
Как видите, процедура срабатывает один раз, а затем выдает ошибку, говоря нам, что представление report_vendor уже имеется в БД. Так происходит потому, что при обращении к процедуре в первый раз, она создает представление. При обращении во второй раз, она снова пытается создать представление, но оно уже есть, поэтому и появляется ошибка. Чтобы избежать этого возможно два варианта.
Первый - вынести представление из процедуры. То есть мы один раз создадим представление, а процедура будет лишь к нему обращаться, но не создавать его. Предварительно не забудет удалить уже созданную процедуру и представление:
Проверяем работу:
call sum_vendor(1)//
call sum_vendor(2)//
call sum_vendor(3)//
Второй вариант - прямо в процедуре дописать команду, которая будет удалять представление, если оно существует:
Перед использованием этого варианта не забудьте удалить процедуру sum_vendor, а затем проверить работу:
Как видите, сложные запросы или их последовательность действительно проще один раз оформить в хранимую процедуру, а дальше просто обращаться к ней, указывая необходимые параметры. Это значительно сокращает код и делает работу с запросами более логичной.
Задание 6. Хранимые процедуры
Теперь давайте узнаем, как можно посмотреть, какие хранимые процедуры имеются у нас на сервере, и как они выглядят. Для этого познакомимся с двумя операторами:
SHOW PROCEDURE STATUS - позволяет просмотреть список имеющихся хранимых процедур. Правда просматривать этот список не очень удобно, т.к. по каждой процедуре выдается информация об имени БД, к которой процедура принадлежит, ее типе, учетной записи, от имени которой была создана процедура, о дате создания и изменения процедуры и т.д. И все-таки, если вам необходимо посмотреть, какие процедуры у вас есть, то стоит воспользоваться этим оператором.
SHOW CREATE PROCEDURE имя_процедуры - позволяет получить информацию о конкретной процедуре, в частности просмотреть ее код. Вид для просмотра также не очень удобный, но разобраться можно.
Попробуйте оба оператора в действии, чтобы знать, как это выглядит. А теперь рассмотрим более удобный вариант получения подобной информации. В системной базе данных MySQL есть таблица proc, где и хранится информация о процедурах. Так вот мы может сделать SELECT-запрос к этой таблице. Причем, если мы создадим привычный запрос:
SELECT * FROM mysql.proc//
То получим нечто такое же нечитабельное, как и при использовании операторов SHOW. Поэтому мы будем создавать запросы с условиями. Например, если мы создадим вот такой запрос:
SELECT name FROM mysql.proc//
То получим имена всех процедур всех баз данных, имеющихся на сервере. Нас, например, на данный момент интересуют только процедуры базы данных shop, поэтому изменим запрос:
SELECT name FROM mysql.proc WHERE db="shop"//
Вот теперь мы получили то, что хотели:
Если же мы хотим посмотреть только тело конкретной процедуры (т.е. от begin до end), то мы напишем такой запрос:
SELECT body FROM mysql.proc WHERE name="sum_vendor"//
И увидим вполне читабельный вариант:
Вообще, чтобы извлекать из таблицы proc необходимую вам информацию, надо просто знать, какие столбцы она содержит, а для этого можно воспользоваться знакомым нам оператором describe имя_таблицы, в нашем случае describe mysql.proc. Правда, вид у нее тоже не очень читабельный, поэтому приведем здесь названия наиболее востребованных столбцов:
db - имя БД, в которую сохранена процедура.
name - имя процедуры.
param_list - список параметров процедуры.
body - тело процедуры.
comment - комментарий к хранимой процедуре.
Столбцы db, name и body мы уже использовали. Запрос, извлекающий параметры процедуры sum_vendor составьте самостоятельно. А вот про комментарии к хранимым процедурам мы сейчас поговорим подробнее.
Комментарии вещь крайне необходимая, ведь через какое-то время мы может забыть, что делает та или иная процедура. Конечно, по ее коду можно восстановить нашу память, но зачем? Гораздо проще сразу при создании процедуры указать, что она делает, и тогда, даже по прошествии долгого времени, обратившись к комментариям, мы сразу вспомним, зачем эта процедура создавалась.
Создавать комментарии крайне просто. Для этого сразу после списка параметров, но еще до начала тела хранимой процедуры указываем ключевое слово COMMENT "здесь комментарий". Давайте удалим нашу процедуру sum_vendor и создадим новую, с комментарием:
А теперь сделаем запрос к комментарию процедуры:
Вообще-то, чтобы добавить комментарий, вовсе не обязательно было удалять старую процедуру. Можно было отредактировать имеющуюся хранимую процедуру с помощью оператора ALTER PROCEDURE. Давайте посмотрим, как это сделать, на примере процедуры ins_cust из прошлого задания. Эта процедура вводит информацию о новом покупателе в таблицу Покупатели (customers). Давайте добавим комментарий к этой процедуре:
ALTER PROCEDURE ins_cust COMMENT
Вводит информацию о новом покупателе в таблицу Покупатели."//
И сделаем запрос к комментарию, чтобы проверить:
SELECT comment FROM mysql.proc WHERE name="ins_cust"//
В нашей базе данных всего две процедуры, и комментарии к ним кажутся излишними. Не ленитесь, обязательно пишите комментарии. Представьте, что в нашей базе данных десятки или сотни процедур. Сделав нужный запрос, вы без труда узнаете, какие процедуры есть и что они делают и поймете, что комментарии - это не излишества, а экономия вашего времени в будущем. Кстати, а вот и сам запрос:
Ну вот, теперь мы умеем извлекать любую информацию о наших процедурах, что позволит нам ничего не забыть и не запутаться.
Задание 7. Хранимые процедуры
Хранимые процедуры это не просто контейнера для групп запросов, как может показаться. Хранимые процедуры могут в своей работе использовать операторы ветвления. Вне хранимых процедур такие операторы использовать нельзя.
Начнем изучение с операторов IF...THEN...ELSE. Если вы знакомы с каким-нибудь языком программирования, то эта конструкция вам знакома. Напомним, что условный оператор IF позволяет организовать ветвление программы. В случае хранимых процедур этот оператор позволяет выполнять разные запросы, в зависимости от входных параметров. На примере, как всегда, будет понятнее. Но для начала синтаксис:
Логика работы проста: если условие истинно, то выполняется запрос 1, в противном случае - запрос 2.
Предположим, каждый день мы устраиваем в нашем магазине счастливые часы, т.е. делаем скидку 10% на все книги в последний час работы магазина. Чтобы иметь возможность выбирать цену книги, нам необходимо иметь два ее варианта - со скидкой и без. Для этого, нам понадобится создать хранимую процедуру с оператором ветвления. Так как мы имеем всего два варианта цены, то удобнее в качестве входящего параметра иметь булево значение, которое, как вы помните, может принимать либо 0 - ложь, либо 1 - истина. Код процедуры может быть таким:
Т.е. на входе у нас параметр, который может являться, либо 1 (если скидка есть), либо 0 (если скидки нет). В первом случае будет выполнен первый запрос, во втором - второй. Давайте посмотрим, как работает наша процедура в обоих вариантах:
call discount(1)//
call discount(0)//
Оператор IF позволяет выбирать и большее количество вариантов запросов, в таком случае используется следующий синтаксис:
CREATE PROCEDURE имя_процедуры (параметры)
IF(условие) THEN
ELSEIF(условие) THEN
Причем блоков ELSEIF может быть несколько. Предположим, что мы решили делать скидки нашим покупателям в зависимости от суммы покупки, до 1000 рублей скидки нет, от 1000 до 2000 рублей - скидка 10%, более 2000 рублей - скидка 20%. Входным параметром для такой процедуры должна быть сумма покупки. Поэтому сначала нам надо написать процедуру, которая будет ее подсчитывать. Сделаем это по аналогии с процедурой sum_vendor, созданной в уроке 15, которая подсчитывала сумму товара по идентификатору поставщика.
Необходимые нам данные хранятся в двух таблицах Журнал покупок (magazine_sales) и Цены (prices).
CREATE PROCEDURE sum_sale(IN i INT)
COMMENT "Возвращает сумму покупки по ее идентификатору."
DROP VIEW IF EXISTS sum_sale;
CREATE VIEW sum_sale AS SELECT magazine_sales.id_sale,
magazine_sales.id_product, magazine_sales.quantity,
prices.price, magazine_sales.quantity*prices.price AS summa
FROM magazine_sales, prices
WHERE magazine_sales.id_product=prices.id_product;
SELECT SUM(summa) FROM sum_sale WHERE id_sale=i;
Здесь перед параметром у нас появилось новое ключевое слово IN. Дело в том, что мы можем, как передавать данные в процедуру, так и передавать данные из процедуры. По умолчанию, т.е. если опустить слово IN, параметры считаются входными (поэтому раньше мы это слово и не использовали). Здесь же мы явно указали, что параметр i является входным. Если же нам понадобится извлечь какие-нибудь данные из хранимой процедуры, то мы будем использовать ключевое слово OUT, но об этом чуть позже.
Итак, мы написали процедуру, которая создает представление, выбирая идентификатор покупки, идентификатор товара, его количество, цену и подсчитывает сумму по всем строчкам получившейся таблицы. Затем идет запрос к этому представлению, где по входному параметру идентификатора покупки подсчитывается итоговая сумма этой покупки.
Теперь нам надо написать процедуру, которая пересчитает итоговую сумму с учетом предоставляемой скидки. Здесь нам и понадобится оператор ветвления:
Т.е. мы передаем процедуре два входных параметра сумму (sm) и идентификатор покупки (i) и в зависимости от того, какая это сумма, выполняется запрос к представлению sum_sale на подсчет итоговой суммы покупки, умноженной на нужный коэффициент.
Осталось только сделать так, чтобы сумма покупки автоматически передавалась в эту процедуру. Для этого процедуру sum_discount хорошо бы вызвать прямо из процедуры sum_sale. Выглядеть это будет примерно вот так:
Вопросительный знак при вызове процедуры sum_discount поставлен, т.к. не понятно, как результат предыдущего запроса (т.е. итоговой суммы) передать в процедуру sum_discount. Кроме того, не понятно, как процедура sum_discount вернет результат своей работы. Вы, наверно, уже догадались, что для решения второго вопроса нам как раз и понадобится параметр с ключевым словом OUT, т.е. параметр, который будет возвращать данные из процедуры. Давайте введем такой параметр ss, и так как сумма может быть и дробным числом, зададим ему тип DOUBLE:
Итак, в обе процедуры мы ввели выходной параметр ss. Теперь вызов процедуры CALL sum_discount(?, i, ss); означает, что передавая два первых параметра, мы ждем возврата третьего параметра в процедуру sum_sale. Осталось только понять, как внутри самой процедуры sum_discount присвоить этому параметру какое-либо значение. Нам надо, чтобы в этот параметр передавался результат одного из запросов. И, конечно, в MySQL предусмотрен такой вариант, для этого используется ключевое слово INTO:
С помощью ключевого слова INTO, мы указали, что результат запроса надо передать в параметр ss.
Теперь давайте разбираться с вопросительным знаком, вернее узнаем, как передать в процедуру sum_discount результат работы предыдущих запросов. Для этого мы познакомимся с таким понятием, как переменная.
Переменные позволяют сохранить результат текущего запроса для использования в следующих запросах. Объявление переменной начинается с символа собачки (@), за которой следует имя переменной. Объявляются они при помощи оператора SET. Например, объявим переменную z и зададим ей начальное значение 20.
Переменная с таким значение теперь есть в нашей БД, можете проверить, сделав соответствующий запрос:
Переменные действуют только в рамках одного сеанса соединения с сервером MySQL. То есть после разъединения переменная перестанет существовать.
Для использования переменных в процедурах используется оператор DECLARE, который имеет следующий синтаксис:
DECLARE имя_переменной тип DEFAULT значение_по_умолчанию_если_есть
Итак, давайте в нашей процедуре объявим переменную s, в которую будем сохранять значение суммы покупки с помощью ключевого слова INTO:
Эта переменная и будет первым входным параметром для процедуры sum_discount. Итак, окончательный вариант наших процедур выглядит так:
На случай, если вы запутались, давайте посмотрим алгоритм работы нашей процедуры sum_sale:
Мы вызываем процедуру sum_sale, указывая в качестве входного параметра идентификатор интересующей нас покупки, например id=1, и указывая, что второй параметр - выходной, переменный, являющийся результатом работы процедуры sum_discount:
call sum_sale(1, @sum_discount)//
Процедура sum_sale создает представление, в котором собираются данные обо всех покупках, товарах, их количестве, цене и сумме по каждой строчке.
Затем выполняется запрос к этому представлению на итоговую сумму по покупке с нужным идентификатором, и результат записывается в переменную s.
Теперь вызывается процедура sum_discount, в которой в качестве первого параметра выступает переменная s (сумма покупки), в качестве второго - идентификатор покупки i, а в качестве третьего указывается параметр ss, который выступает, как выходной, т.е. в него вернется результат действия процедуры sum_discount.
В процедуре sum_discount проверяется, какому условию соответствует входная сумма, и выполняется соответствующий запрос, результат записывается в выходной параметр ss, который возвращается в процедуру sum_sale.
Чтобы увидеть результат работы процедуры sum_sale нужно сделать запрос:
select @sum_discount//
Давайте убедимся, что наша процедура работает:
Сумма наших обеих покупок меньше 1000 рублей, поэтому скидки нет. Можете самостоятельно ввести покупки с разными суммами и посмотреть, как будет работать наша процедура.
Возможно, этот урок показался вам достаточно трудным или запутанным. Не расстраивайтесь. Во-первых, все приходит с опытом, а во-вторых, справедливости ради, надо сказать, что и переменные, и операторы ветвления в MySQL используются крайне редко. Предпочтение отдается языкам типа PHP, Perl и т.д., с помощью которых и организуется ветвление, а в саму БД посылаются простые процедуры.
Задание 8. Хранимые процедуры
Сегодня узнаем, как работать с циклами, т.е. выполнять один и тот же запрос несколько раз. В MySQL для работы с циклами применяются операторы WHILE, REPEAT и LOOP.
Оператор цикла WHILE
Сначала синтаксис:
WHILE условие DO
Запрос будет выполняться до тех пор, пока условие истинно. Давайте посмотрим на примере, как это работает. Предположим, мы хотим знать названия, авторов и количество книг, которые поступили в различные поставки. Интересующая нас информация хранится в двух таблицах - Журнал Поставок (magazine_incoming) и Товар (products). Давайте напишим интересующий нас запрос:
А что, если нам необходимо, чтобы результат выводился не в одной таблице, а по каждой поставке отдельно? Конечно, можно написать 3 разных запроса, добавив в каждый еще одно условие:
Но гораздо короче сделать это можно с помощью цикла WHILE:
Т.е. мы ввели переменную i, по умолчанию равную 3, сервер выполнит запрос с id поставки равным 3, затем уменьшит i на единицу (SET i=i-1), убедится, что новое значение переменной i положительно (i>0) и снова выполнит запрос, но уже с новым значением id поставки равным 2. Так будет происходить, пока переменная i не получит значение 0, условие станет ложным, и цикл закончит свою работу.
Чтобы убедиться в работоспособности цикла создадим хранимую процедуру books и поместим в нее цикл:
Теперь вызовем процедуру:
Теперь у нас 3 отдельные таблицы (по каждой поставке). Согласитесь, что код с циклом гораздо короче трех отдельных запросов. Но в нашей процедуре есть одно неудобство, мы объявили количество выводимых таблиц значением по умолчанию (DEFAULT 3), и нам придется с каждой новой поставкой менять это значение, а значит код процедуры. Гораздо удобнее сделать это число входным параметром. Давайте перепишем нашу процедуру, добавив входной параметр num, и, учитывая, что он не должен быть равен 0:
Убедитесь, что с другими параметрами, мы по-прежнему получаем таблицы по каждой поставке. У нашего цикла есть еще один недостаток - если случайно задать слишком большое входное значение, то мы получим псевдобесконечный цикл, который загрузит сервер бесполезной работой. Такие ситуации предотвращаются с помощью снабжения цикла меткой и использования оператора LEAVE, обозначающего досрочный выход из цикла.
Итак, мы снабдили наш цикл меткой wet вначале (wet:) и в конце, а также добавили еще одно условие - если входной параметр больше 10 (число 10 взято произвольно), то цикл с меткой wet следует закончить (IF (i>10) THEN LEAVE wet). Таким образом, если мы случайно вызовем процедуру с большим значением num, наш цикл прервется после 10 итераций (итерация - один проход цикла).
Циклы в MySQL, так же как и операторы ветвления, на практике в web-приложениях почти не используются. Поэтому для двух других видов циклов приведем лишь синтаксис и отличия. Вряд ли вам доведется их использовать, но знать об их существовании все-таки надо.
Оператор цикла REPEAT
Условие цикла проверяется не в начале, как в цикле WHILE, а в конце, т.е. хотя бы один раз, но цикл выполняется. Сам же цикл выполняется, пока условие ложно. Синтаксис следующий:
UNTIL условие
Оператор цикла LOOP
Этот цикл вообще не имеет условий, поэтому обязательно должен иметь оператор LEAVE. Синтаксис следующий:
На этом мы заканчиваем изучение SQL. Конечно, мы рассмотрели не все возможности этого языка запросов, но в реальной жизни вам вряд ли придется столкнуться даже с тем, что вы уже знаете.
Размещено на Allbest.ru
...Подобные документы
Использование встроенных функций MS Excel для решения конкретных задач. Возможности сортировки столбцов и строк, перечень функций и формул. Ограничения формул и способы преодоления затруднений. Выполнение практических заданий по использованию функций.
лабораторная работа , добавлен 16.11.2008
Особенности использования встроенных функций Microsoft Excel. Создание таблиц, их заполнение данными, построение графиков. Применение математических формул для выполнения запросов с помощью пакетов прикладных программ. Технические требования к компьютеру.
курсовая работа , добавлен 25.04.2013
Назначение и составляющие формул, правила их записи и копирования. Использование математических, статистических и логических функций, функций даты и времени в MS Excel. Виды и запись ссылок табличного процессора, технология их ввода и копирования.
презентация , добавлен 12.12.2012
Рассмотрение особенностей объявления функций на языке СИ. Определение понятий аргументов функции и их переменных (локальных, регистровых, внешних, статических). Решение задачи программным методом: составление блок-схемы, описание функций main и sqr.
презентация , добавлен 26.07.2013
Правили создания и алгоритм применения собственной функции пользователя в стандартном модуле редактора VBA. Изучение структуры кода функции. Перечень встроенных математических функций редактора Visual Basic. Определение области видимости переменной.
практическая работа , добавлен 07.10.2010
Создание приложения, которое будет производить построение графиков функций по заданному математическому выражению. Разработка программы "Генератор математических функций". Создание мастера функций для ввода математического выражения, тестирование.
дипломная работа , добавлен 16.02.2016
Проведение анализа динамики валового регионального продукта и расчета его точечного прогноза при помощи встроенных функций Excel. Применение корреляционно-регрессионного анализа с целью выяснения зависимости между основными фондами и объемом ВРП.
реферат , добавлен 20.05.2010
Функции, позволяющие работать с базой данных MySQL средствами РНР. Соединение с сервером и его разрыв. Создание и выбор базы данных. Доступ к отдельному полю записи. Комплексное использование информационных функций. Запросы, отправляемые серверу MySQL.
лекция , добавлен 27.04.2009
Разработка приложения, которое будет выполнять функции показа точного времени и точной даты. Определение дополнительных функций разработанного приложения. Рассмотрение основных этапов создания программного продукта. Результаты тестирования приложения.
курсовая работа , добавлен 14.04.2019
Программное вычисление по формулам, определение площади правильного многоугольника для любых возможных исходных данных, использование потоков ввода-вывода. Использование операторов при вычислении математических функций, алгоритмы накопления суммы.